切断正規分布(Truncated normal distribution)
腕をバッサリ切り落とし切断正規分布
上限と下限
さて、突然ですが袋に30グラムと書いてある某メーカーヒット商品のスナック菓子がここにあります。
突撃訪問にて工場で次々と作られる製品の重さを量ってみるとピッタリ30グラムなわけもなく、29.98グラムのものもあれば、30.12グラムのものもあったりします。 もちろん30グラム周辺にデータは固まっていて、極端に多すぎるものや少なすぎるものは少なくなっています。そうです。ピンときましたか?これはまさに「正規分布」をなす典型的な場合だったのです!(テンション高めに左側の図をご覧ください。)
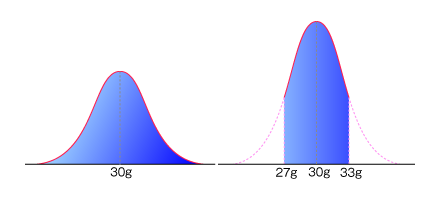
では、忘れていましたが、我々の手元にあるこの製品の重さはどうなっているのでしょうか。
早速大人買いをして、重さの分布を見てみることにしましょう。さすが30グラムと書いてあるだけのことはあって、大体どれも30グラムに近い値ですが、ピッタリ30グラムなわけもなく、29.98グラムのものもあれば、30.12グラムのものもありますね(ま、当たり前なんですが)。 こうして努力と不意の出費の結果出来あがった分布図は右側のものになりました。
ここで左と異なる点がはっきりします。我々の手元に届いたという条件の下では グラムより誤差が大きいものが存在しないのです!すると分布は裾をバッサリ切り取られたような形になってしまいます。 しかし存在範囲では依然、正規分布であることは間違いないのです。
そう、この分布こそが切断正規分布なのです。
条件付確率
さていきなりここで問題です。図を見ると右の分布は左右の両側を切り取っただけでなく、背が高くなっていることに気がつきましたか?これは何故でしょうか?
そうです、確率の基礎を熟知しているあなたなら(アナタですよ、アナタ!)もう明らかでしょう。そう、確率密度関数の曲線の下の面積は1でないといけないからです(ちゃんと覚えてましたか?)。
もともと面積が1だった正規分布の曲線(図の左)から単純にに左右を切り取ると、面積は1より小さくなってしまいますね。そこで、面積が1になるように縦に引き伸ばしているのです。すごいでしょう?
そしてこれは、条件付確率の事実を表現しているのです。つまり、この状況下では
「我々の手元に来た、という条件の下で重さが 以下になる確率は?」
という問いを表現したものが求める分布関数であったのです。まさに条件付確率ではないでしょうか。
「我々の手元に来る確率」は左の図で左右の裾を切り取った部分の面積に他ならないですよね(平均グラムに収まる確率)。従って、分布関数は、単に左右を切り取ったものを「我々の手元に来る確率」で割ったものになるのです。
その他
-
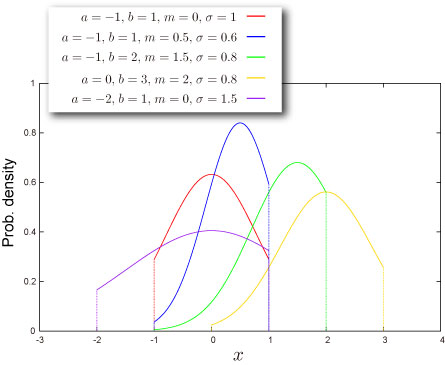
実は上限と下限は必ずしも分布の山を挟む必要はないのです。下図のように山を挟まないで分布の裾の部分だけを残したような切断正規分布ももちろん考えられます(何に使われるかは現在調査中ですが)。

-
上限と下限を定めた切断正規分布を「両側切断正規分布」、上限または下限のみを定めた切断正規分布を「片側切断正規分布」と呼ぶことがあります。
分布の形状
基本情報
-
4つのパラメータ が必要です (どうやって求めるの?).
-
有限区間 で定義された連続分布です。
-
平均対して対称にも非対称にもなり得ます。
確率
-
ここで
、 は 標準正規分布の累積分布関数です。
-
Excel での累積分布関数 (c.d.f.) と 確率密度関数 (p.d.f.)の求め方
| A | B | |
|---|---|---|
| 1 | データ | 説明 |
| 2 | 2.5 | 対象となる値 |
| 3 | 1 | 分布のパラメータ Min の値 |
| 4 | 4 | 分布のパラメータ Max の値 |
| 5 | 3 | 分布のパラメータ M の値 |
| 6 | 0.9 | 分布のパラメータ Sigma の値 |
| 7 | 数式 | 説明(計算結果) |
| 8 | =NTTRUNCNORMDIST(A2,A3,A4,A5,A6,TRUE) | 上のデータに対する累積分布関数の値 |
| 9 | =NTTRUNCNORMDIST(A2,A3,A4,A5,A6,FALSE) | 上のデータに対する確率密度関数の値 |
- 関連 NtRand 関数 : NTTRUNCNORMDIST
分位点
| A | B | |
|---|---|---|
| 1 | データ | 説明 |
| 2 | 0.5 | 上のデータに対する確率密度関数の値 |
| 3 | 1 | 分布のパラメータ Min の値 |
| 4 | 4 | 分布のパラメータ Max の値 |
| 5 | 3 | 分布のパラメータ M の値 |
| 6 | 0.9 | 分布のパラメータ Sigma の値 |
| 7 | 数式 | 説明(計算結果) |
| 8 | =NTTRUNCNORMINV(A2,A3,A4,A5,A6) | 上のデータに対する累積分布関数の逆関数の値 |
- 関連 NtRand 関数 : NTTRUNCNORMINV
分布の特徴
平均 -- 分布の"中心"はどこ? (定義)
| A | B | |
|---|---|---|
| 1 | データ | 説明 |
| 2 | 1 | 分布のパラメータ Min の値 |
| 3 | 4 | 分布のパラメータ Max の値 |
| 4 | 3 | 分布のパラメータ M の値 |
| 5 | 0.9 | 分布のパラメータ Sigma の値 |
| 6 | 数式 | 説明(計算結果) |
| 7 | =NTTRUNCNORMMEAN(A2,A3,A4,A5) | 上のデータに対す分布の平均 |
- 関連 NtRand 関数 : NTTRUNCNORMMEAN
標準偏差 -- 分布はどのくらい広がっているか(定義)
| A | B | |
|---|---|---|
| 1 | データ | 説明 |
| 2 | 1 | 分布のパラメータ Min の値 |
| 3 | 4 | 分布のパラメータ Max の値 |
| 4 | 3 | 分布のパラメータ M の値 |
| 5 | 0.9 | 分布のパラメータ Sigma の値 |
| 6 | 数式 | 説明(計算結果) |
| 7 | =NTTRUNCNORMSTDEV(A2,A3,A4,A5) | 上のデータに対する分布の標準偏差 |
- 関連 NtRand 関数 : NTTRUNCNORMSTDEV
歪度 -- 分布はどちらに偏�っているか(定義)
| A | B | |
|---|---|---|
| 1 | データ | 説明 |
| 2 | 1 | 分布のパラメータ Min の値 |
| 3 | 4 | 分布のパラメータ Max の値 |
| 4 | 3 | 分布のパラメータ M の値 |
| 5 | 0.9 | 分布のパラメータ Sigma の値 |
| 6 | 数式 | 説明(計算結果) |
| 7 | =NTTRUNCNORMSKEW(A2,A3,A4,A5) | 上のデータに対する分布の歪度 |
- 関連 NtRand 関数 : NTTRUNCNORMSKEW
尖度 -- 尖っているか丸まっているか (定義)
| A | B | |
|---|---|---|
| 1 | データ | 説明 |
| 2 | 1 | 分布のパラメータ Min の値 |
| 3 | 4 | 分布のパラメータ Max の値 |
| 4 | 3 | 分布のパラメータ M の値 |
| 5 | 0.9 | 分布のパラメータ Sigma の値 |
| 6 | 数式 | 説明(計算結果) |
| 7 | =NTTRUNCNORMKURT(A2,A3,A4,A5) | 上のデータに対する分布の尖度 |
- 関連 NtRand 関数 : NTTRUNCNORMKURT
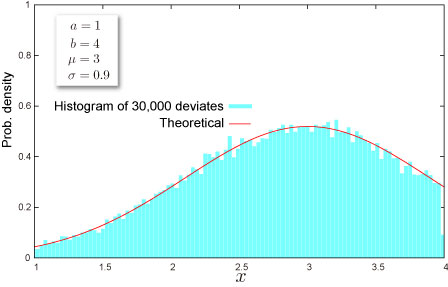
乱数
| A | B | |
|---|---|---|
| 1 | データ | 説明 |
| 2 | 1 | 分布のパラメータ Min の値 |
| 3 | 4 | 分布のパラメータ Max の値 |
| 4 | 3 | 分布のパラメータ M の値 |
| 5 | 0.9 | 分布のパラメータ Sigma の値 |
| 6 | 数式 | 説明(計算結果) |
| 7 | =NTRANDTRUNCNORM(100,A2,A3,A4,A5,0) | 切断正規乱数を Mersenne Twister アルゴリズムで生成します。 |
メモ: この使用例の数式は、配列数式として入力する必要があります。使用例を新規ワークシートにコピーした後、A7:A106 のセル範囲 (配列数式が入力されているセルが左上になる) を選択します。F2 キーを押し、Ctrl キーと Shift キーを押しながら Enter キーを押します。この数式が配列数式として入力されていない場合、単一の値 2 のみが計算結果として返されます。
関連 NtRand 関数
- 既に分布のパラメータをお持ちの場合
- Mersenne Twiseter 法による乱数生成 : NTRANDTRUNCNORM
- 確率計算 : NTTRUNCNORMDIST
- Computing quantile : NTTRUNCNORMINV
- 平均計算 : NTTRUNCNORMMEAN
- 標準偏差計算 : NTTRUNCNORMSTDEV
- 歪度計算 : NTTRUNCNORMSKEW
- 尖度計算 : NTTRUNCNORMKURT
- 上記の各モーメントを一度に計算 : NTTRUNCNORMMOM
- 分布の平均と標準偏差をお持ちの場合
- 分布のパラメータ推定 : NTTRUNCNORMPARAM
参照
-
Marketing
"Use of the Left-Truncated Normal Distribution for Improving Achieved Service Levels" by Arvid C. Johnson
-
Agriculte