 RSS
RSSGlossary
A simple improvement method of Monte Carlo’s convergence. When a normal random number is generated, change its sign to produce a new random number. This makes all the odd moments (e.g., mean, skewness) turned zero with a significant increase in convergence. A normal random numbers sequence generated by antithetic variant method is self-explanatory.
Excel performs multiple-calculation using array formula and returns multiple results at a time. To input the array formula, select the desired cell for output, type the expression, and then press CTRL+SHIFT+ENTER. For further information, see the topic about “Array Formula” in your Excel Online Help.
Why I always see the same result even if I input formula into multiple cells?
=\int_{0}^{1}t^{x-1}(1-t)^{y-1}\text{d}t")
The simplest method of converting uniform random numbers into normal random numbers. The conversion is applicable to one sequence of pseudo-random numbers.
}") is defined as:
is defined as:
}=\int_{-\infty}^{+\infty}(x-\mu)^kf(x)\text{d}x")
where ")

NtRand has three pseudo random number generator algorithms. The selection is made by 2nd argument (Algorithm) of each random number functions.
- Algorithm=0: Mersenne Twister 2002
Produce 53bit precision (0, 1) uniform real random numbers by revised Mersenne Twister algorithm released 1/26/2002. At this moment, this is the ‘standard’ Mersenne Twister. In this implementation, its random seed is 64 bit width. I recommend this algorithm in most of the case. - Algorithm=1: Mersenne Twister 1998
Mersenne Twister used within Version 1.x NtRand. Its random seed is 64 bit width. Previous Mersenne Twister algorithm had a small problem. The highest bit of the seed is not well reflected to the state vector. The problem is reported in Mersenne Twister home page, and TT800 problem report. The reports say Jeff Szuhay reveals the problem to MT’s small cousin TT800. However, this is not so ‘small’ problem and I also detected in 1998. So I modified MT slightly when I released NtRand in 1998. My resolution is to project 64bit random seed into 32bit space, and avoid this reflection problem. (I didn’t report the problem like Jeff does. Sorry, Prof. Matsumoto.) From the first release in 1998, NtRand uses this algorithm. Now, the ‘standard’ Mersenne Twister algorithm has released, I won’t recommend my resolution. Use this option only if you want to keep backward compatibility. - Algorithm=2: Numerical Recipes ran2
This is the recommended random number generator algorithm in the book, W. H. Press, S. A. Teukolsky, W. T. Vetterling, B. P. Flannery, Numerical Recipes in C 2nd ed., Cambridge Univ. Press, 1992. This is very famous algorithm and it has long period (> 2 x 1018). However, unfortunately, the algorithm doesn’t pass many random number quality tests (e.g. 2-dimensional random walk, n-block test, etc.). It has clear correlation problem and I don’t recommend this especially for multi-dimensional Monte Carlo simulation. There are several other algorithms in Numerical Recipes book, however, all of them are no good.
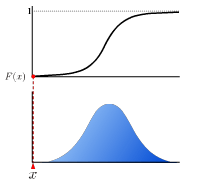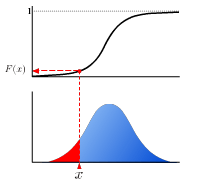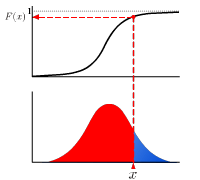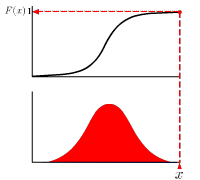
The real-valued function which describes the probability distribution of a real-valued random variable. The value at x represents the probability that the variable has value less than or equal to x.
\sim 0.577215")
=\int_{0}^{+\infty}t^{x-1}\text{e}^{-t}\text{d}t")
=\int_{0}^{x}t^{p-1}(1-t)^{q-1}\text{d}t")
This is identical to beta function when x=1.
Normalized incomplete beta function are defined by
=\frac{B_x(p,q)}{B(p,q)}")
where ")
=\int_{0}^{x}\text{e}^{-u}u^{a-1}\text{d}u")
One method of the uniform/normal random numbers conversions. Performs conversion by applying the approximate expression obtained by Taylor’s expansion while dividing it in intervals. In Quasi Monte Carlo, the combined use of Box-Muller and quasi-random number does not bring an expected improvement due to the problem of Box-Muller method in uniform/normal random numbers conversion. Thus, the inverse function method, rather complicated than the Box-Muller, must be applied.
}}{\sigma^4}-3")
where }")

This is also known as “excess kurtosis”
Leptokurtic means the distribution has fat tail. Mathematically, kurtosis is positive.
Mean is interpreted as typical location of the distribution or weighted center of the distribution.

The probability density function transfers without changing its form when the mean is varying.
It is computed as 1st. raw moment of the distribution. It is represented as “m” in almost all text book.
The position at which the probability density function is separated into two parts whose area are the same each other.
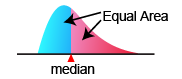
Median is computed as
")
, where ")
An algorithm which generates uniform pseudo random numbers with longer period and higher order of equidistribution. (See Mersenne Twister home page)
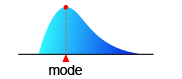
The value that occurs the most frequently in a data set or a probability distribution. For the probability density function which has a single peak, the mode is the position of the peak.
Multiple number of normal random number sequences which are correlational to each other. These make the key in multivariate simulation such as Monte Carlo VaR.
A sequence of random numbers that has the mean value of 0 and standard deviation of 1 when its statistics is collected.
Physical random numbers (Wikipedia – Random number generation)
Leptokurtic means the distribution has thin tail. Mathematically, kurtosis is negative.
The real-value function which describes the relative likelihood for this random variable to occur at a given point in the observation space.
- always positive
- Area below the curb of function on the range between x=a and x=b represents a probability that the variable x have a value between a and b.

- Whole area below the curb of function is one.
- The function is characterized by median, mode, mean, standard deviation, skewness, kurtosis and so on.
A function characterize the discrete distribution as:
![Pr[X=x]=p(x)](http://s0.wp.com/latex.php?latex=Pr%5BX%3Dx%5D%3Dp%28x%29&bg=T&fg=000000&s=0 "Pr[X=x]=p(x)")
This is corresponding to probability density function for continuous distribution function.
Computer-generated random numbers are not actually the true random numbers. Thus, they are called “pseudo” random numbers.
Generate random numbers for the desired number, calculate the statistics of entire random number sequences, then offset the random numbers with the obtained statistics. This method enables to adjust the 2nd moment which the antithetic variant cannot eliminate. Normally, this method is used with the antithetic variant method. In NtRand, the quadratic resampling is implemented based on the know-how in 1990. Regarding the recent quadratic resampling method, some participant employs the higher order of even-order moment matching.
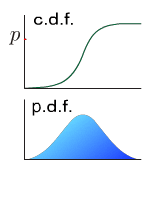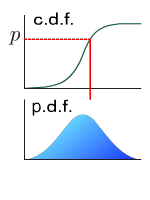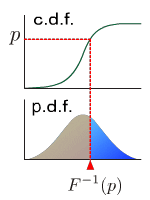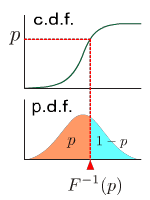
| p-quantile is the value at which the distribution is divided into two parts with probabilities p and (1-p) respectively. This is the value of inverse function of cumulative distribution function at p. |
|
}") is defined as:
is defined as:
}=\int_{-\infty}^{+\infty}x^kf(x)\text{d}x")
where
- The 0th raw moment is one.
- The 1st raw moment is mean of the distribution.
See Incomplete beta function
=\sum_{n=1}^{\infty}\frac{1}{n^x}")
=\frac{\pi^2}{6}\sim 1.645")
\sim 1.202\quad\text{(a.k.a. Ap\'{e}ry's constant)}")
=\frac{\pi^4}{90}\sim 1.0823")
One of the triangular decomposition methods of matrix. To generate a multivariate correlated random numbers, the covariance matrix entered in the generation process shall be split into two triangular matrices. Square rooting and Cholesky decomposition are convenient methods and covered in elementary textbooks for their application in real symmetric positive definite matrix. For the larger amount of non-correlated data, the split Cholesky decomposition assuming a “band matrix” with narrower condition doubles the computing efficiency compared to the standard Cholekey method. However, to compute by using the higher dimension of economic time-series data, securing the inter-sequence independency is difficult and the assumption of the positive definite matrix is too strict. Under the higher dimensional environment, solutions may not be stable because of the increased possibility to encounter the underflow error in the process of repeating operation in the computer. In this case, the improved SVD is an effective and practicable method.
}}{\sigma^3}")
where }")
Uniform random numbers distribute constantly in [0,1] interval. As random numbers are usually obtained in the form of uniform random numbers, you need to convert them to normal random numbers. This process is called uniform/normal random numbers conversion.
Random numbers uniformly distributed in the [0,1] interval.
A unimodal probability distribution is a probability distribution which has a single mode. Rectangle shaped distributions such as the uniform distribution does not have a mode.
 . This is a square of standard deviation.
. This is a square of standard deviation.

