 RSS
RSS指数分布(Exponential distribtuion)
雑踏の中を歩く指数分布
都会の雑踏を歩いていると、1メートル進んでは人にぶつかり、3メートル進んでは人にぶつかり、となかなかスムーズに歩けないですよね(え、私だけ?)。直感的に考えて
- 長い距離ぶつからずに歩ける確率は少ない
- 人がたくさんいると短い距離歩くだけでぶつかる
まず、雑踏をそのままモデル化するのは難しそうです。そこで簡単なモデルを考えることにします。
歩いている人間は複雑すぎるので、1本道上で人はみんな止まっていると仮定します。ある人の場所から歩いて、次の人までぶつからずに歩く。 このモデルで人と人との間隔の分布を調べてみましょう。
このモデルでもいきなり一般的な話をすると難しいから、更に簡単な状況からスタートすることにしますね。
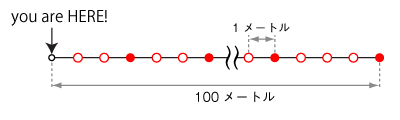
さて、100メートルの道があります。自分の今いる場所から1メートル先の地点、そこから100個のベンチが1メートル間隔で並んでいます。そこに20人の人が座ることとします。ただし以下の条件の制約があります。
- 1つのベンチには1人しか座れない。
- 座り心地の良いベンチがあるとか、日陰と日なたにあるベンチがあるとか、嫌いな奴から離れて座りたいとか、どこかのベンチにモデル級の美女が座っていて、その周辺に何人か集まって座るとか、そういったことはありません。つまりどのベンチに座るかは「同様に確からしい」のです。
 となります。
となります。では勇気を持って歩き出してください。
- 隣のベンチに人はいなかった
- その隣のベンチにも人はいなかった
- その隣のベンチには人がいた
先ず隣のベンチに人がいない確率は

 であることを思いだして)。
その隣にも人がいないので、ここまでの確率は
であることを思いだして)。
その隣にも人がいないので、ここまでの確率は
^2")
^2\times0.2")
ここまで来れば、あるベンチから右側に
 個分のベンチに人がいなくて、その次に人がいる(つまりメートル人と出会わない)確率は、
個分のベンチに人がいなくて、その次に人がいる(つまりメートル人と出会わない)確率は、
^x\times0.2")
では次ステップに移りましょう。ベンチの数を倍にして50センチ間隔に配置してみます。ベンチの数は倍の200個、人の数は変わらず20人になるので、ベンチに人がいる確率は 0.1 となりますね。
こで
 個のベンチを挟んで、次のベンチに人がいる(つまりメートル人と出会わない)確率は、
個のベンチを挟んで、次のベンチに人がいる(つまりメートル人と出会わない)確率は、
^{2x}\times0.1")
さらにベンチの間隔を半分にします。ベンチが400個、人は20人。
 個のベンチを挟んで、次に人がいる(つまりメートル人と出会わない)確率は、
個のベンチを挟んで、次に人がいる(つまりメートル人と出会わない)確率は、
^{4x}\times0.05")
ここまでの様子を図に示してみます(
 の場合)。
の場合)。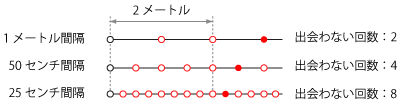
もうここまでくれば、一般化は簡単ですね。
 としましょう。
としましょう。^{x/\delta}\times\delta\frac{n}{N}")
") と書くと、隣の人ととの距離が
と書くと、隣の人ととの距離が ") メートル以下である確率が
メートル以下である確率が
-F(x)")
-F(x)=\left(1-\delta\frac{n}{N}\right)^{x/\delta}\times\delta\frac{n}{N}")
-F(x)}{\delta}=\left(1-\delta\frac{n}{N}\right)^{x/\delta}\times\frac{n}{N}")
 の極限(つまりバラバラのベンチではなく、100メートルの長いすに自由に座る)を考えると、
の極限(つまりバラバラのベンチではなく、100メートルの長いすに自由に座る)を考えると、
=\frac{1}{\beta}\exp\left(-\frac{x}{\beta}\right)")

 メートルに1回ぶつかるとすると(イタイ)、
メートルに1回ぶつかるとすると(イタイ)、 とした
とした
 で定義された連続分布です。
で定義された連続分布です。=1-\exp\left(-\frac{x}{\beta}\right)")
=-\beta\ln(1-P)")
 です。
です。
 です。
です。
")

