Mar 19, 2013
複利の場合
となります。これが離散的な場合の結果であり、議論のスタート台となります。
こいつの連続極限を考えます。
知りたいことは、連続極限で
具体的には、
といったことを調べます。
式(5)、、、掛け算のままだと取扱いが難しいので、両辺の対数をとりましょう。
ここに伝家の宝刀、テイラー展開
を適用します。定石通り1次の項だけとると式(6)は、
となって、これは正に単利の場合と同一の式でキレイに正規乱数の和に収束することが分かりました。
つまり 正規分布 になることが判明しました(覚えていますか?正規乱数の和は正規乱数です)。
さてこれで
対数をとったヤツが正規分布になった という事実から連続極限で であると結論付けられました!
では平均と分散はどうなるでしょうか。
式(8)から、
でメデタシメデタシ、、、としたいところですが、これが大間違い! 。本記事の核心がここにあります。
話はテイラー展開 (7)にまで戻ります。
2次の項まで考えます。すると
となります。
この式から平均を計算してみます。
となって、ここで
となります。そして連続極限
が得られます。気が付きましたか?テーラー展開の2次の近似項から
分散も同じ要領で計算してみると、こちらは2次の近似項は
です。
以上まとめると、
となります。
標準正規分布に従う確率変数
と書き下せます。
最後にもう一言
対数正規分布の公式 から、
が得られます。どうですか?実に合理的な答えになっていると思いませんか?(その1 の式(3)と比較してみてください)。
長くなりましたが、あのキモチワルイ
Mar 19, 2013
発生する金利の利率が乱数だったらどうなるか?さすがに何の仮定もないと話が進まないので、
金利(年率)は、平均 という場合を論じましょう。
第
と与えられます(ここで
式(4)は年率なので、半期分、つまり年2回の利払いがある場合の各回の利率は、
と与えられます。一般に年
となります。
単利の場合
となります。
ここで「正規乱数の和は正規乱数になる 」という、もはや犬でも知っている事実から、
分布の特徴は以下の通り。
平均:
分散:
以上より、
という分布になることが判明しました。
金利が毎回変わったとしても、この式中に年間利払回数
さて次は複利の場合ですが、、、これがチトややこしいので、その3に続く
Mar 19, 2013
先ずは準備運動
元金が
単利の場合
年間に利払いが
うーん文句なし。まったくもってあたりまえだ。
複利の場合
上記と同様に利率は
となります。
次に上記の式で連続極限 と呼ばれる操作です。
これは年間の利払い回数が無限大、つまり無限に短い期間に無限に小さい利率による利払いが発生し、それが無限に積み重なった場合を考えることです。
単利の場合
式(1)の中にNが含まれていないので
複利の場合
式(2)で
連続極限で指数関数になります。
と、まぁこんな話はどの金融の教科書にも最初のページに書いてあります。
さて上記のケースは全て金利が一定値金利が乱数 だったらどうなるでしょうか。それが今回の記事で書きたいことです。
その2へ続く、、、
Jul 17, 2012
2人が同時に好きな自然数を叫びます。
ではもう一度
ではここで問題「任意に2つの数字が互いに素である確率は?」
ちょっと実験してみようにもこれはなかなか難しいです。
さあ数字を言え!といってこんな数字を挙げられる人はいないでしょう。
じゃあコンピューターで、といっても無限にある自然数をすべて公平に挙げるのは無理でしょう。
しかし人間の知性に限界はありません。この問題を理論的に解きましょう。
例えば、8と16の公約数は2、4、8となりますが、互いに素かどうかを見るには素数の公約数だけみればいいということに注目します。
この例なら4で割れるかどうかを調べはしません。素数2で割れるかを見るだけです。
任意の自然数
同様に素数5で割れる確率は1/5、素数13で割れる確率は1/13、、、素数
従って自然数
ということは自然数公約数に持たない確率 は
自然数
です。なんとも複雑そうな式ですが、この値は幾らになるでしょうか?
結論だけ言うと、
です。なんとこんなところに円周率が出てきます!
Feb 09, 2012
火星に生物はいるだろうか?生物のいる確率はどのくらいだろうか?順を追って求めてみよう。
まずは火星に人間がいる確率を
よし、次に火星に犬がいる確率を
どんどん続けよう。次に火星にアメンボがいる確率を
ここで中間報告。では、火星に人間も犬もアメンボもいない 確率はいくつになるだろうか。それは、”(人間がいない)かつ(犬がいない)かつ(アメンボがいない)”確率となるので、次式で与えられる。
なるほど…しかし、まだ他にも調査すべき生物はたくさんある!象がいる確率、マントヒヒがいる確率、ムカデがいる確率、カピバラがいる確率…どれもきっと確率は0ではないだろう。
ある生物がいる確率をまったく生物がいない 確率は、
となる。ちょっと待てよ、、、ということは、火星に何か生物がいる 確率は、
これは驚いた!火星にはきっと何かいるぞ!
上記の推論はどこがおかしいか分かりますが?
Dec 20, 2011
「二人の子供問題」という有名な確率のトピックです。
昼休み。食事も終えて、職場の仲間とまったりとコーヒーを飲んでいます。誰ともなしに家族の話題になりました。
独りモノのあなたな職場の仲間Aさんにこんな質問をしました。
では、ここで問題
あなたはAさんに更に質問をぶつけました。
なるほど。では、ここで問題
もう一人Bさんが隣に座っています。Bさんは今日はたまたま子供を連れてきています。男の子です。
あなたはBさんにも質問をしました。
ふーむ、、、ここで問題
問2と問3の違いが分かりますか?AさんもBさんも二人子供がいて、少なくとも一人は男の子であることが分かっています。
ちなみに解答は(男の子が生まれる確率と女の子が生まれる確率は等しいとしましょう)
です。
Dec 20, 2011
確率のネタではないですが、小話をひとつ
NtRandでは”Mersenne-Twister”と呼ばれる一様乱数生成アルゴリズムが採用されています。
このアルゴリズムで生成される乱数は
さて、この数は”メルセンヌ素数”と呼ばれる一群の数字のうちの一つで、これが”Mersenne-Twister”の語源になっています。
メルセンヌ素数とは、素数のうちで
1644年、マラン・メルセンヌさんが
更に残念なことに、、、
1903年、アメリカで行われた数学会でフランク・ネルソン・コールなる人物が発表のため登壇しました。タイトルは「大きな数の素因数分解」。
彼はまず黒板に
そこから1を引き、そして次に
の計算を行いました。その結果は、、、
メルセンヌさんの主張から250年以上経って、
今では
May 25, 2010
某国、華やかなカジノの街。
ルーレット、スロットマシーン、カード…有象無象どもが一攫千金を目論んで目を血走らせて必死にもがいている。
さて今日はどのゲームでひと稼ぎしようか…ふと片隅にあるゲームに目がとまる。
「サイコロを転がして出た目が1なら1円、2なら2円…出た目と同じ額を賞金として進呈!」
なんとも幼稚なギャンブルだが、まぁいいや。ちょっとやってみるか。
参加費用は4円か。サイコロなんだから5か6を出せばもうかるじゃないか、チョロイチョロイ。
…1時間後…
すっかりスッカラカンになった彼は道端でボロ雑巾のようになっていた。
もちろん、確率を熟知したあなたはこのゲームには参加しないはずですね。
そう、期待値の問題です。このゲームの賞金の期待値
は、
です。賞金は 3.5円しか期待できないのに参加費が4円。長い目でみるとどんどんと負けが込んでいくのです(ちなみに1枚300円の宝くじの期待値は大体142円だそうです)。
リベンジだとばかりに再びカジノにやってきた彼。今度は確率の勉強もしっかりしてきた。
うーん、どのゲームも期待値を計算するとマイナスのものばかりか(当たり前。ギャンブルは胴元が儲かるようになっている)…なまじ確率の勉強をしたのでどのゲームも割に合わないと感じてしまうなぁ。
ふと片隅にあるゲームに目がとまる。
「コイントスゲーム!外れなし!表が出たら賞金は倍!!ただし裏が出たらゲームオーバー」
つまり、
1回目で裏が出たら賞金1円
2回目で裏が出たら賞金2円
3回目で裏が出たら賞金4円
4回目で裏が出たら賞金8円
(以下賞金は倍々)
なるほど面白そうだ。おっといけない、軽々に飛びついては痛い目に逢う。まずは期待値を計算してみよう。
各パターンの確率は、
裏:
表裏:
表表裏:
表表表裏:
表表表表裏:
(あとは分かるでしょう)
となるので、期待値は
こりゃ凄い、何と
期待値は無限大 だ!幾らでも儲かるってことか!!で、参加費はいくらだって?1億円か。安い安い!!よ~し、やるぞ!!!…はたして彼の運命やいかに…
どうです?あなたはこのゲームに参加しますか?参加費100円でもやらないのではないでしょうか?(ちなみに100円以上の賞金を手にするには、7回連続して表を出す必要があります)。
でも確かに期待値は無限大…腑に落ちませんね。これが「サンクトペテルブルグのパラドックス」です。
May 24, 2010
複数の確率変数があるとき、それらがてんでバラバラ好き勝手に変動しているとき「無相関」という言葉を使います。
また「独立」という言葉もあります。
どちらも何となく似たような意味合いなので、混同している(というか気にしていない)場合もあるようですが、もちろんこの2つは異なる定義があります。
では「無相関」と「独立」の関係を見てみましょう。
「独立」なら「無相関」か?
その通り!「独立」の方が強いです。これはまぁ言葉通りのイメージではないでしょうか。「独立」しているのに何らかの関連性があるとは考えにくいです。
「無相関」なら「独立」か?
これは
違います! 。お互いに関連せずに変動していても「独立」でない場合があります。
これを理解するにはやはり「相関」を正しく理解することが必要です。
相関の定義は、
です。細かい内容はさておき、重要なのは相関はデータ全体でひとつの値、つまり平均や標準偏差と同じデータの特徴を現す量であることです。
平均は分布の位置、標準偏差は分布の広がり具合です。では相関が何を表す量か?それは下の Flash で確認してください。
相関係数が 0 つまり無相関の場合とそうでない場合のデータプロットの違いが分かりましたか?無相関だと分布が全体としてまん丸になるになりますね。もっとも無相関だからといって分布がまん丸になるとは限りませんが、少なくともまん丸なら無相関です。
では下のようなプロットはどうでしょう?
このプロット (x, y) を生成する確率変数 X と Y は無相関です(まん丸で、どっちに傾けても変化なし)。しかしこの図をみて X と Y が勝手に変動していると認識する人はいないでしょう(たとえば X が 0付近なら、Y は
付近しか値がとれない)。
May 24, 2010
モンテカルロシミュレーションの第1歩として、100パーセントどの教科書にも載っている例題があります。
どの教科書にも載っていて、このサイトに無いのも悔しいので載せておきます。
一様乱数から円周率を求めよう
1辺が1の正方形を用意します。そこに4分の1円を描いておきます。この正方形内に一様に点を打っていき、
(円内の点の数)/(全点の数) を計算すると、
これは
(4分の1円面積)/(正方形の面積) に近づいていきます。
(4分の1円面積)/(正方形の面積)はすなわち
なので、(円内の点の数)×4 /(全点の数)は円周率
に近づいていきます。
Older Entries
 RSS
RSS=V_0\cdot\prod_{i=1}^{TN}r_i(N)=V_0\cdot\prod_{i=1}^{TN}\left(\frac{\sigma}{\sqrt{N}}{\cdot} z_i+\frac{m}{N}+1\right)")
")
={\ln}V_0+\sum_{i=1}^{TN}\ln\left(\frac{\sigma}{\sqrt{N}}{\cdot}z_i+\frac{m}{N}+1\right)")
=x-\frac{x^2}{2}+\frac{x^3}{3}-\cdots")
= {\ln}V_0+\sum_{i=1}^{TN}\left(\frac{\sigma}{\sqrt{N}}{\cdot}z_i+\frac{m}{N}\right)")
")
 元は対数正規分布
元は対数正規分布![E\left[{\ln}V(T)\right]={\ln}V_0+mT](http://s0.wp.com/latex.php?latex=E%5Cleft%5B%7B%5Cln%7DV%28T%29%5Cright%5D%3D%7B%5Cln%7DV_0%2BmT&bg=T&fg=000000&s=0 "E\left[{\ln}V(T)\right]={\ln}V_0+mT")
![V\left[{\ln}V(T)\right]=\sigma^2 T](http://s0.wp.com/latex.php?latex=V%5Cleft%5B%7B%5Cln%7DV%28T%29%5Cright%5D%3D%5Csigma%5E2+T&bg=T&fg=000000&s=0 "V\left[{\ln}V(T)\right]=\sigma^2 T")
={\ln}V_0+\sum_{i=1}^{TN}\left(\frac{\sigma}{\sqrt{N}}{\cdot}z_i+\frac{m}{N}\right)-\frac{1}{2}\sum_{i=1}^{TN}\left(\frac{\sigma}{\sqrt{N}}{\cdot}z_i+\frac{m}{N}\right)^2")
![E\left[{\ln}V(T)\right]={\ln}V_0+mT-\frac{1}{2}\sum_{i}^{TN}\left[\frac{\sigma^2}{N}E(z_i^2)+2\sigma m\sqrt{N}E(z_i)+\frac{m^2}{N^2}\right]](http://s0.wp.com/latex.php?latex=E%5Cleft%5B%7B%5Cln%7DV%28T%29%5Cright%5D%3D%7B%5Cln%7DV_0%2BmT-%5Cfrac%7B1%7D%7B2%7D%5Csum_%7Bi%7D%5E%7BTN%7D%5Cleft%5B%5Cfrac%7B%5Csigma%5E2%7D%7BN%7DE%28z_i%5E2%29%2B2%5Csigma+m%5Csqrt%7BN%7DE%28z_i%29%2B%5Cfrac%7Bm%5E2%7D%7BN%5E2%7D%5Cright%5D&bg=T&fg=000000&s=0 "E\left[{\ln}V(T)\right]={\ln}V_0+mT-\frac{1}{2}\sum_{i}^{TN}\left[\frac{\sigma^2}{N}E(z_i^2)+2\sigma m\sqrt{N}E(z_i)+\frac{m^2}{N^2}\right]")
=0,\;E(z_i^2)=1")
![E\left[{\ln}V(T)\right]={\ln}V_0+mT-\frac{\sigma^2}{2}T-\frac{m^2T}{2N}](http://s0.wp.com/latex.php?latex=E%5Cleft%5B%7B%5Cln%7DV%28T%29%5Cright%5D%3D%7B%5Cln%7DV_0%2BmT-%5Cfrac%7B%5Csigma%5E2%7D%7B2%7DT-%5Cfrac%7Bm%5E2T%7D%7B2N%7D&bg=T&fg=000000&s=0 "E\left[{\ln}V(T)\right]={\ln}V_0+mT-\frac{\sigma^2}{2}T-\frac{m^2T}{2N}")

![E\left[{\ln}V(T)\right]={\ln}V_0+mT-\frac{\sigma^2}{2}T](http://s0.wp.com/latex.php?latex=E%5Cleft%5B%7B%5Cln%7DV%28T%29%5Cright%5D%3D%7B%5Cln%7DV_0%2BmT-%5Cfrac%7B%5Csigma%5E2%7D%7B2%7DT&bg=T&fg=000000&s=0 "E\left[{\ln}V(T)\right]={\ln}V_0+mT-\frac{\sigma^2}{2}T")

![V\left[\ln V(T)\right]=\sigma^2 T](http://s0.wp.com/latex.php?latex=V%5Cleft%5B%5Cln+V%28T%29%5Cright%5D%3D%5Csigma%5E2+T&bg=T&fg=000000&s=0 "V\left[\ln V(T)\right]=\sigma^2 T")
{\sim} N\left({\ln}V_0+mT-\frac{\sigma^2}{2}T,\sigma^2T\right)")

![V(T)=V_0\exp\left[\sigma\sqrt{T}Z+\left(m-\frac{\sigma^2}{2}\right)T\right]](http://s0.wp.com/latex.php?latex=V%28T%29%3DV_0%5Cexp%5Cleft%5B%5Csigma%5Csqrt%7BT%7DZ%2B%5Cleft%28m-%5Cfrac%7B%5Csigma%5E2%7D%7B2%7D%5Cright%29T%5Cright%5D&bg=T&fg=000000&s=0 "V(T)=V_0\exp\left[\sigma\sqrt{T}Z+\left(m-\frac{\sigma^2}{2}\right)T\right]")
T")
![E\left[V(T)\right]=V_0\exp(mT)](http://s0.wp.com/latex.php?latex=E%5Cleft%5BV%28T%29%5Cright%5D%3DV_0%5Cexp%28mT%29&bg=T&fg=000000&s=0 "E\left[V(T)\right]=V_0\exp(mT)")

 、標準偏差
、標準偏差 の正規乱数
の正規乱数 回目の利払金利(年率)は、
回目の利払金利(年率)は、 —(4)
—(4) は標準正規乱数)。
は標準正規乱数)。=\frac{\sigma}{\sqrt{2}}{\cdot}{z_i}+\frac{m}{2}")
=\frac{\sigma}{\sqrt{N}}{\cdot}{z_i}+\frac{m}{N}")
![V(T)=V_0+\sum_{i=1}^{TN}r_i(N)=V_0\cdot\left[1+\sum_{i=1}^{TN}\left(\frac{\sigma}{\sqrt{N}}{\cdot}{z_i}+\frac{m}{N}\right)\right]](http://s0.wp.com/latex.php?latex=V%28T%29%3DV_0%2B%5Csum_%7Bi%3D1%7D%5E%7BTN%7Dr_i%28N%29%3DV_0%5Ccdot%5Cleft%5B1%2B%5Csum_%7Bi%3D1%7D%5E%7BTN%7D%5Cleft%28%5Cfrac%7B%5Csigma%7D%7B%5Csqrt%7BN%7D%7D%7B%5Ccdot%7D%7Bz_i%7D%2B%5Cfrac%7Bm%7D%7BN%7D%5Cright%29%5Cright%5D&bg=T&fg=000000&s=0 "V(T)=V_0+\sum_{i=1}^{TN}r_i(N)=V_0\cdot\left[1+\sum_{i=1}^{TN}\left(\frac{\sigma}{\sqrt{N}}{\cdot}{z_i}+\frac{m}{N}\right)\right]")
![E[V(T)]=V_0+\sum_{i}^{TN}\frac{m}{N}=V_0+mT](http://s0.wp.com/latex.php?latex=E%5BV%28T%29%5D%3DV_0%2B%5Csum_%7Bi%7D%5E%7BTN%7D%5Cfrac%7Bm%7D%7BN%7D%3DV_0%2BmT&bg=T&fg=000000&s=0 "E[V(T)]=V_0+\sum_{i}^{TN}\frac{m}{N}=V_0+mT")
![V[V(T)]=\frac{\sigma^2}{N}\cdot\sum_{i=1}^{TN}V[z_i]=\sigma^2 T](http://s0.wp.com/latex.php?latex=V%5BV%28T%29%5D%3D%5Cfrac%7B%5Csigma%5E2%7D%7BN%7D%5Ccdot%5Csum_%7Bi%3D1%7D%5E%7BTN%7DV%5Bz_i%5D%3D%5Csigma%5E2+T&bg=T&fg=000000&s=0 "V[V(T)]=\frac{\sigma^2}{N}\cdot\sum_{i=1}^{TN}V[z_i]=\sigma^2 T")
{\sim}{N}(V_0+mT,\sigma^2T)")
 、利率を
、利率を (年率)とした場合の単利と複利の場合それぞれで、
(年率)とした場合の単利と複利の場合それぞれで、  年後の元利合計を改めて考えてみましょう(何を今更、、、)。
年後の元利合計を改めて考えてみましょう(何を今更、、、)。 となったうえで
となったうえで 回つくのでの元利合計は、
回つくのでの元利合計は、=V_0+V_0\cdot\underbrace{(r/N+r/N+\cdots+r/N)}_{TN \text{times}}=V_0\cdot(1+rT)") —(1)
—(1)=V_0\cdot\underbrace{(1+r/N)(1+r/N)\cdots(1+r/N)}_{TN \text{times}}=V_0\cdot(1+r/N)^{TN}") —(2)
—(2)=V_0\cdot\exp(rT)") —(3)
—(3) で割れる確率は、
で割れる確率は、 であるというのは分かりますか?
であるというのは分かりますか? となります。つまり全自然数の3つに1つが素数3で割れる自然数だということになります。
パッと選んだ自然数が3で割れるかは3つに1つ、つまり確率1/3となります。
となります。つまり全自然数の3つに1つが素数3で割れる自然数だということになります。
パッと選んだ自然数が3で割れるかは3つに1つ、つまり確率1/3となります。 となります。
となります。 と
と がどちらも素数
がどちらも素数 となります。
となります。 となります。
となります。")
=\frac{6}{\pi^2}=0.607927\cdots")
 という部分は「バーゼル問題」という数学の歴史的難問(解決に100年!)に端を発し、数学の最大の未解決問題とされる「リーマン予想」にも関わるネタで、
とてもここでは書ききれません。
という部分は「バーゼル問題」という数学の歴史的難問(解決に100年!)に端を発し、数学の最大の未解決問題とされる「リーマン予想」にも関わるネタで、
とてもここでは書ききれません。 としよう。例えば…
としよう。例えば… くらいかな。
くらいかな。 としよう。なんとなく犬は人間よりいそうなんで、
としよう。なんとなく犬は人間よりいそうなんで、 とでもしてみるか。
とでもしてみるか。 としよう。これはきっと人間なんかよりずーっといる確率が高いだろう。よし
としよう。これはきっと人間なんかよりずーっといる確率が高いだろう。よし だ。
だ。(1-P_\text{dog})(1-P_\text{water strider})")

 とする。
とする。 とすると、火星にまったく生物がいない確率は、
とすると、火星にまったく生物がいない確率は、=(99.999999\%)^{100000000}\sim 37\%")

 、実に6002桁という途方もない長い周期をもっています。
、実に6002桁という途方もない長い周期をもっています。 という形で書けるもののことです。
つまりMarsenne-Twisterの周期は
という形で書けるもののことです。
つまりMarsenne-Twisterの周期は のメルセンヌ素数です。
2001年5月現在、メルセンヌ素数は47個見つかっています。
のメルセンヌ素数です。
2001年5月現在、メルセンヌ素数は47個見つかっています。 がメルセンヌ素数であると主張しました。
残念なことに彼は
がメルセンヌ素数であると主張しました。
残念なことに彼は を見逃していました。
を見逃していました。 を書き下しました。
を書き下しました。

 !
その間彼は一言も口をきかず、静かに席に戻りました。その後会場は万雷の拍手が沸いたそうです。
!
その間彼は一言も口をきかず、静かに席に戻りました。その後会場は万雷の拍手が沸いたそうです。 が素数でないことが分かったのです。
が素数でないことが分かったのです。 も素数ではないことが分かっています。
も素数ではないことが分かっています。 は、
は、


^2")
^3")
^4")
^5")
^2+4\times\left(\frac{1}{2}\right)^3+8\times\left(\frac{1}{2}\right)^4+\cdots=\frac{1}{2}+\frac{1}{2}+\frac{1}{2}+\cdots=+\infty")
(y_{i}-\bar{y})")
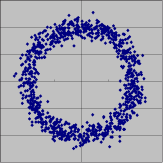
 付近しか値がとれない)。
付近しか値がとれない)。 なので、(円内の点の数)×4 /(全点の数)は円周率
なので、(円内の点の数)×4 /(全点の数)は円周率  に近づいていきます。
に近づいていきます。
